Stránka 19 z 80
Re: DirectX 12 - info a vše okolo
Napsal: pon 8. čer 2015, 16:06
od hadas
Re: DirectX 12 - info a vše okolo
Napsal: úte 9. čer 2015, 13:01
od del42sa
Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 10:42
od Krteq
Ache píše:Tomu neveřim, že to sčítání bude fungovat.
Otázka zní jak by to mohlo fungovat, když karty mezi sebou jsou propojeny 16GB/s sběrnicí, po které opravdu se netahají jen textury?

PCI-E 3.0 16x Full-Duplex je 32GB/s, přes CFX/SLi můstek protlačíš max. 900MB/s, tak jaká zas limitace?
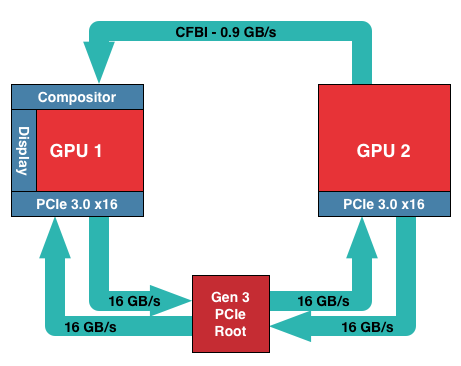
//
AnandTech píše: With that in mind, the specific role of the XDMA engine is relatively simple. Located within the display controller block (the final destination for all completed frames) the XDMA engine allows the display controllers within each Hawaii GPU to directly talk to each other and their associated memory ranges, bypassing the CPU and large chunks of the GPU entirely. Within that context the purpose of the XDMA engine is to be a dedicated DMA engine for the display controllers and nothing more. Frame transfers and frame presentations are still directed by the display controllers as before – which in turn are directed by the algorithms loaded up by AMD’s drivers – so the XDMA engine is not strictly speaking a standalone device, nor is it a hardware frame pacing device (which is something of a misnomer anyhow). Meanwhile this setup also allows AMD to implement their existing Crossfire frame pacing algorithms on the new hardware rather than starting from scratch, and of course to continue iterating on those algorithms as time goes on.
Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 10:48
od Ache
Krteq píše:
Full Duplex je sice hezký, ale jedním směrem máš 16GB/s, a bude tohle stačit i na to aby si kromě klasických render dat co přes to tečkou ještě prohazoval textury mezi čipy.
Jednoduchá situace: Hra co fakt bude vyžadovat ještě+ více textur než takový SoM. Dejme tomu, čistě teoreticky 7GB
Ok? Na statickým snímku dejme tomu že si ty grafiky mezi sebou rozdělí obraz tak, že každá bude míst na sobě naloadováno 3,5GB textur který použije na svojí část... To by asi fungovalo.
Ale v pohybu kdy se začne hráč otáče a pobíhat?
Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 10:50
od no-X
Ache píše:Tomu neveřim, že to sčítání bude fungovat.
Otázka zní jak by to mohlo fungovat, když karty mezi sebou jsou propojeny 16GB/s sběrnicí, po které opravdu se netahají jen textury?
S AFR by to obecně moc dobře nešlo.
V SFR by to ve specifických případech mohlo vést ke zlepšení. Zkus si představit situaci, kdy je scéna rozdělená vodorovně a zároveň jsou nároky na paměť tak vysoké, že při normální AFR, kdy se kapacita nesčítá, onboard paměť nestačí, GPU přímo přistupuje k texturám do RAM a výkon proto padá. Teď bys namísto AFR použil SFR, texturu země hodil do paměti karty, která vykresluje spodek, texturu nebe do paměti karty, která vykresluje vršek. Najednou by paměť stačila a framerate by mohl být i několikanásobně vyšší. I v případě, že by byly určité přesahy a např. "dolní" GPU vykreslovalo i kousek nebe z paměti "horního" GPU, by stále byl framerate vyšší, protože by se 90 % vykreslovalo za použití textur v onboard paměti.
Třetí případ: V nových API je možné rozdělit vykreslování i na objekty. Takže máš možnost do paměti GPU, které bude vykreslovat pajďuláčky, naskládat třeba textury pajďuláčků a do druhého GPU textury prostředí.
Nemyslím, že by byl problém v tom, že to nebude fungovat, ale spíš v tom, kolik vývojářů toho využije, když je to v podstatě práce navíc, kterou 99,99 % reálných hráčů nedokáže ocenit.
Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 11:01
od DOC_ZENITH
Jedině na oběkty, něco jako textury země jinam než textury oblohy na bázi pozice na obrazovce a o které GPU tu část zrovna bere je neymslitelné, při jakémkoliv pohybu kamery by se textury musely přesouvat což by to naprosto zabilo. Pokud se má načátat kapacita textur musí to bejt object based. Samo sebou SFR umožňuje dělit kapacitu framebufferu, bude se dělit počtem GPU.
Pokud se to má masivně rozšířit, musí to fungovat automaticky, nevidim důvod proč by object based rendering, když už bude fungovat, nemohl fungovat automaticky dle ňákého HW či SW load balanceru. Dokonce by tak šlo kombinovat různě výkonná GPU, a to navíc v libovolném počtu. A hlavně by to fungovalo docela dobře bez stutteru, atd, nebyl by to useless stutterfest jako je dnes kombinování různě rychlejch GPU (APU s diskrétní GPU k němu v hybrid crossfire budiž odstrašujícim příkladem).
Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 11:06
od Krteq
To už je na diskuzi do DX12 vlákna, tady to neřešte.
Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 11:15
od Ache
No do tohohle tématu se do dá snad zavřít jen tím, že 2x4GB Fiji ani pod DX12 nebude to samé, jako by jsi měl 1x 8GB Fiji... ale pokud to bude chytře fungovat, je dost možné že že ze 4+4GB grafik se efektivně a bez problémů využije třeba 6GB.
Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 11:27
od DOC_ZENITH
Jistě že nebude, to by byl schopen vyplivnout leda marketing AMD, resp, se to tak už dělá běžně, X2ky maj na krabici sečtenou paměť.
Btw ten diagram propojení čiů mi hodně připomíná 3Dlabs Wildcat 800, ala znovu oběvujem Ameriku. V další generaci přijde konečně i exterí sdílenej framebuffer ke kterému se budou připojovat jednotlivá GPU co budou mít jen SP a TMU, HBM se k tomu doslova nabázej.
Dle mého názoru to dříve či později tímto směrem půjde, GPU se stanou modulárními.
Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 11:51
od CZ_viper
No u mé "bývalé" GTX690 bylo na krabici taky 4 GB a přitom to bylo 2x 2 GB.

Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 12:02
od Hladis
K tomu SFR
....but now that we see geometric tessellation and complex shading effects becoming much more common, the pitfalls of screen-portioned rendering (split-frame, scissor frame, supertiling, etc.) become a lot more pronounced. Overdrawing is the biggest problem here; all of the vertices for scene geometry have to be transformed by each GPU even if they are not within the GPU's assigned region, meaning geometry performance cannot scale like it does with AFR, and any polygon between multiple rendering regions has to be fully textured and shaded by each GPU whose region it occupies, which is wasteful. Of course, there are also complications that can rise from inaccurate workload allocations.
Takze z toho mi vychazi snizeny geometricky vykon a vetsi nároky na pametovy systém. Ted DX12 sice umoznuje vetsi kontrolu GPU a co která bude delat, ale to zase znamena vysoky nároky na vyvojare to spravne do aplikace narvat.
A presunu to do DX12 tématu.
Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 12:21
od DOC_ZENITH
CZ_viper píše:No u mé "bývalé" GTX690 bylo na krabici taky 4 GB a přitom to bylo 2x 2 GB.
Ano to neplatí jen pro AMD, i 3DFX v době Voodoo 5 udávala sečtenou paměť.

Hladis píše:K tomu SFR........ Takze z toho mi vychazi snizeny geometricky vykon a vetsi nároky na pametovy systém. Ted DX12 sice umoznuje vetsi kontrolu GPU a co která bude delat, ale to zase znamena vysoky nároky na vyvojare to spravne do aplikace narvat.
A presunu to do DX12 tématu.
O geometrickej výkon bych se nebál, dnešní GPU v něm maj naprostej overkill.
Re: AMD Pirate Islands (R9 300) - informace, spekulace
Napsal: pát 12. čer 2015, 12:23
od no-X
DOC_ZENITH píše:Jedině na oběkty, něco jako textury země jinam než textury oblohy na bázi pozice na obrazovce a o které GPU tu část zrovna bere je neymslitelné, při jakémkoliv pohybu kamery by se textury musely přesouvat což by to naprosto zabilo.
Nemusely a nepřesouvaly by se. Podstata tkví v tom, že jádro může texturovat přímo z libovolné paměti. Vlastní, operační i paměti druhé (třetí, čtvrté...) grafiky.
Re: DirectX 12 - info a vše okolo
Napsal: pát 12. čer 2015, 12:32
od DOC_ZENITH
NJN, za předpokladu že by byly jednotlivé memory pooly spojené a bandwitch byl dostatečnej. (eghm kam že nám to zmizel sideport...).
Já si myslim ž tam jednoho dne dojdem, GPU se rozdělí, jeden čip bude komunikovat s PCI-E plus dělat geometrii, a ten bude mít svou fast paměť a tam také bude framebuffer. Ostatní čipy můžou mít slow paměť cílenou na kapacitu a budou všechny propojené na ten řídicí, přidáním dalších GPU se jen rozšíří ten pool pro textury a zvedne se hrubej výkon TMU/SP. Tzn stejnej koncept jako 3Dlabs Wildcat 800, jen vše modernější, vyspělejší a a rychlejší.
Ihmo Intel Iris, ten už taky funguje na tom že framebufffer je jinde než textury a jak ho to boostnulo. HBM jev podle mě přestuní stanice než se framebuffer začne dělat jen jako masivní cache. Si vezměte jak melej by ten blok co by dělal TMU/SP/paměť ori textury byl, kdyby to by jen čip plus malé dva HBM moduly, díky menšímu počtu a nárokům na prostupnost by i složitost řadiče a interposeru poklesla, atd.
Re: DirectX 12 - info a vše okolo
Napsal: pát 12. čer 2015, 12:33
od Krteq
no-X píše:DOC_ZENITH píše:Jedině na oběkty, něco jako textury země jinam než textury oblohy na bázi pozice na obrazovce a o které GPU tu část zrovna bere je neymslitelné, při jakémkoliv pohybu kamery by se textury musely přesouvat což by to naprosto zabilo.
Nemusely a nepřesouvaly by se. Podstata tkví v tom, že jádro může texturovat přímo z libovolné paměti. Vlastní, operační i paměti druhé (třetí, čtvrté...) grafiky.
Jj, stejně jako u Mantle se jedná o jednotný adresní prostor

In traditional APIs, when you create an object like an image or a buffer, the driver implicitly allocates memory for you. [That] seems okay, but it has a number of problems. It's difficult to efficiently recycle memory; you're going to have bigger memory footprints because of that; creating the object itself is more expensive, because you have to go to the OS to get the GPU memory; and the driver becomes inefficient, because it spends a lot of time managing these OS video memory handles to work with the display driver model.
In Mantle, API objects are simple CPU-side info that have no memory explicitly attached. Instead, you as the app developer allocate GPU memory explicitly and bind it to the object.
Re: DirectX 12 - info a vše okolo
Napsal: pát 12. čer 2015, 13:14
od no-X
DOC_ZENITH píše:NJN, za předpokladu že by byly jednotlivé memory pooly spojené a bandwitch byl dostatečnej. (eghm kam že nám to zmizel sideport...).
Mým cílem bylo poukázat na to, že v okamžiku, kdy s AFR dojde paměť a hra místo 60 FPS poběží na 15 FPS, může specifické SFR se sdílenou pamětí nabídnout alternativu, která limit v podobě nedostatečné paměti odstraní, hra poběží třeba na 50 FPS a jen v případech, kdy se v obrazové části jednoho GPU objeví příliš textur uložených v paměti druhého GPU, bude výkon klesat. Teoreticky by ale ani v nejhorším možném případě neměl klesnout pod těch 15 FPS, na nichž běžel v AFR.
DOC_ZENITH píše:Ihmo Intel Iris, ten už taky funguje na tom že framebufffer je jinde než textury a jak ho to boostnulo.
Ano, ale je třeba hodnotit i dopady na výrobní náklady (z nichž se odvozuje koncová cena). L4 Iris Pro je obrovský kus křemíku, který negeneruje žádný vlastní výkon, jen omezuje vliv jednoho limitu. Srovnej si to na reálných produktech: Grafika 14nm Broadwellu je díky 128MB L4 jenom o 20 % rychlejší než grafika 28nm Kaveri, která používá výlučně pomalé DDR3 a nemá ani delta-kompresi. Se 14nm procesem by jádro Kaveri taky mohlo běžet na 1GHz+ a s delta-kompresí navrch by jistě bylo rychlejší než Iris Pro (i se stávajícími pomalými DDR3). L4 Iris Pro nevnímám jako technologickou výhodu, ale jako berličku, která sice zmírní limitaci ze strany DDR3, ale na úkor takového navýšení ceny, že to z čipu udělá butikovou záležitost.
Herní grafiky tímhle směrem nepůjdou. HBM jsou projektované jako paměti běžných nákladů, jenom začátek výroby je drahý, protože bylo třeba zavést nové výrobní postupy a vyladit je. Oddělená paměť pro frame-buffer a textury nemůže v PC sféře fungovat z jednoho prostého důvodu: Kapacita frame-bufferu omezuje výstupní rozlišení. Zatímco u integrované grafiky nebo konzolí, které jsou postavené pro konkrétní rozlišení (třeba 1080p a s ničím víc se nepočítá) může být paměť frame-buffer poměrně malá a levná, v desktopu se řeší 4k a 5k. Těžko si představit, nakolik by taková ~1GB eDRAM vyšla. Navíc po zavedení delta-komprese mají i HBM mnohem vyšší propustnost než je třeba, takže tady myslím limit není.
To už by bylo zajímavější urychlit nástup optického PCIe a zvýšit rychlost, kterou mohou jednotlivá GPU v systému vzájemně komunikovat. Čím vyšší dostupná rychlost, tím efektivnější způsoby grafického multiprocesingu je možné nasadit.
Re: DirectX 12 - info a vše okolo
Napsal: pát 12. čer 2015, 13:51
od webwalker
Imho SFR asi pouze jen rozděluje obraz na části a každá grafika si řeší tu svou. Paměti se pak samozřejmě sčítají. Rozdělení renderování podle objektů na scéně si myslím, že by bylo složitější páč nevím, jak by se prováděl třeba pixel depth test. No ale kdo ví? Color buffer, Z-buffer a Stencil buffer by pak musel nějak společný, nebo každý gpu by měl svou kopii?
To, že si SFR bude muset programovat každý sám je jen dobře. Ostatně to platí i pro DX12 jako takové, snad už bude konec toho, že se chyby ve hrách budou napravovat v ovladačích místo toho, aby jako Joudové je muselo opravovat AMD či Nvidia.
Stejně tak bude zajímavé, jestli vůbec bude možné zaměňovat shadery v driverech za lépe napsané pro danou uarch. User mode kernel tam sice je, ale už není centrální.
Hladis//Vydeleni prispevku. http://pctforum.tyden.cz/viewtopic.php? ... 9#p8886489
Re: DirectX 12 - info a vše okolo
Napsal: stř 29. črc 2015, 15:39
od Krteq
Re: DirectX 12 - info a vše okolo
Napsal: čtv 30. črc 2015, 09:35
od blekota je boss
kdy a na čem si budu moct to zázračný DX12 vyzkoušet? jsou nějaký dema?
Re: DirectX 12 - info a vše okolo
Napsal: čtv 30. črc 2015, 11:24
od Hladis
Na Fermi se v Nv tak nejak zatím vysrali a sami to psali, ze to bude mit podporu se spozdenim. Hold priority jsou jinde a nV musí resit podporu pro tri architektury


{kind=link}