Re: AMD Vega - Info, spekulace
Napsal: sob 12. led 2019, 11:17
Hm 64 rops  Takze se ani nesnazili odstranit bottlenecky.Proste portli vegu 64 na 7nm.
Takze se ani nesnazili odstranit bottlenecky.Proste portli vegu 64 na 7nm.
Diskuze o hardware, software a overclockingu
https://forum.pctuning.cz/
del42sa píše:napojení ROP´s na memory controller jasné nebylo a IMHO se ani z těch schémat vyčíst nedalo
AnandTech píše:AMD has significantly reworked how the ROPs (or as they like to call them, the Render Back-Ends) interact with their L2 cache. Starting with Vega, the ROPs are now clients of the L2 cache rather than the memory controller, allowing them to better and more directly use the relatively spacious L2 cache.
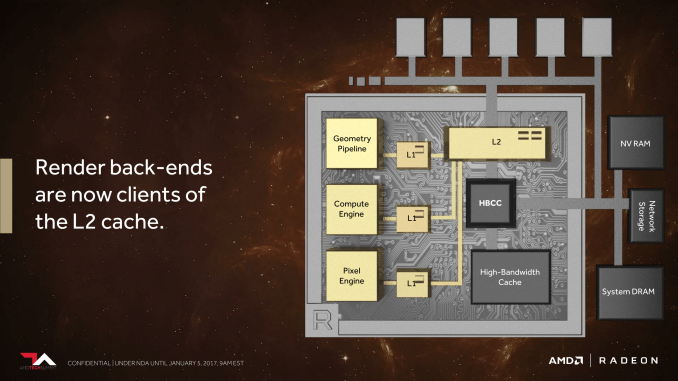
jasné to není, protože L2 je přece přímo napojená na paměťový řadič a jehož jsou právě ty ROP´s klientem nebo ?Krteq píše:Já myslel že je to jasné už od roku 2016
AnandTech píše:AMD has significantly reworked how the ROPs (or as they like to call them, the Render Back-Ends) interact with their L2 cache. Starting with Vega, the ROPs are now clients of the L2 cache rather than the memory controller, allowing them to better and more directly use the relatively spacious L2 cache.
o port se určitě nejednáHEAD píše:Hm 64 rops
Tak to si mal naznacene asi uz na tej prezentacii vykonu od AMD ze to nieje ziadna slava takze to tak s najvacsiou pravedpodobnostou asi bude. Zaujimalo by ma skor kde vzali ten prezentovany narast vykonu vo Falloute.HEAD píše:Hm 64 rops

Finally, AMD is connecting Vega’s ROPs directly to its L2 cache. This will boost performance in games that use deferred rendering because it allows the GPU’s render backends to write directly to L2 rather than moving data through main memory first.
O.K. já to vzdávám. Po bitvě je každej generál, žes to nenapsal předtím, když se tady spekulovalo na téma 128 bit ROP´s ....Krteq píše:
To je hodne zajimava uvaha. Pri pohledu na Greenland(VEGA 10) si clovek rika WTF.DOC_ZENITH píše:Tohlencto s FP64 na 1/2, tunou dalších low-precision GPGPu modů a 4x HBM stacky s ECC korekcí si myslim že je to co měla Vega původně bejt, ale to co nakonec vypadlo na 14nm byl těžkej kompromis protože už tak to bylo moc nákladný, žravý a velký. Kdyby ta arch byla efektivnější aby to šlo realizovat na 14nm a tohle jsme dostali ke konci roku 2016 byla by dnes situace na trhu zdravá. Takhle je to jen další "too little too late".
ano, ale dávalo se do souvislosti s čím asi ? s dvojnásobným počtem HBM kanálů nebo ?Krteq píše:Však jsem několikrát psal že se s počtem 128 ROPs spekulovalo a zdvojnásobení ROPs na jeden cluster.
pokud to takhle (vůbec) bylo, tak se spíš nabízí otázka proč ? AMD se nikdy spotřebou čipů netrápilo, takže by mě zajímal spíše ten důvod té změny. Už to že nevyšel velký čip Greenland ve stejnou dobu jako Polaris je zvláštní.... Možná že v té době GloFo ještě nebylo schopné vyrobit na relativně novém výrobním procesu 14nm velký čip ...yuri.cs píše:Nevim, jestli je tam dost prostoru na to, aby se tam vesel planovany Greenland jako VEGA 20 na 14nm, ktery by mel vyjit nekdy po Polarisu v 2016. Pak tedy zruseny a predelany na VEGU 10.
ježíši a četl jsi to Anandovo zdůvodnění těch 128 ROP´s ? Vždyť to tam psali a dávali to do souvislosti právě s 4096bit busem u HBM2Krteq píše:Se 128 ROPs přišel AnandTech, ale netušil jsem z čeho to vzali. Čekal jsem že mají info od AMD.
No, VEGA 10 na 14nm nema 1/2 speed FP64, polovinu pameti, externi I/O a stejne se horko tezko drzi v 300W TDP.del42sa píše:pokud to takhle (vůbec) bylo, tak se spíš nabízí otázka proč ? AMD se nikdy spotřebou čipů netrápilo, takže by mě zajímal spíše ten důvod té změny. Už to že nevyšel velký čip Greenland ve stejnou dobu jako Polaris je zvláštní.... Možná že v té době GloFo ještě nebylo schopné vyrobit na relativně novém výrobním procesu 14nm velký čip ...
ano, ale vyšla o rok později, těch 300 W mohla mít klidně už v roce 2016 a nikdo by se nezlobil....yuri.cs píše:No, VEGA 10 na 14nm nema 1/2 speed FP64, polovinu pameti, externi I/O a stejne se horko tezko drzi v 300W TDP.
No nevim jaky predstavy meli, kdyz to cmarali na papir, ale tohle rozhodnuti je stalo pomerne draho. Aby Vega nejak byla konkurenceschopna, tak potrebuje o dost lepsi vyrobni proces a super rychly a super drahy 16GB HBM2. Odmyslime, ze to i tak strasne zere a efektivita neni dobra. Nevim zda jim nemohlo byt uz v dobe projektovani jasny, ze tohle bude hodne draha a ne moc efektivni sranda, zvlaste kdyz nV uz mavala Maxwellem. Nevim zda si pri navrzich uvedomovali ekonomickou stranku veci vyrobnich nakladu. Dle tehdejsiho dost sebevedomyho marketingu to vypadalo, ze si mysli, jaky vyrabeji delo. Na papire se jim to mohlo zdat super a treba tomu fakt verili.DOC_ZENITH píše:myslim že je to co měla Vega původně bejt
Tohle neni portnuta Vega 64 na 7nm, ale s predstihem planovana Vega 20 a jaky "bottlenecky" by tam meli odstranovat, kdyz ta uarch byla davno hotova a je dana. To by to museli cely zahodit a udelat uarch novou, coz jaksi by znamenalo nedat na trh vubec nic. To jsou takovy ty hospodsky predstavy jako u Bulldozeru a jak dojde k oprave bottlenecku a bude z toho delo. Prdlajs, Bulldozer skoncil cely v kosi a vytvorili ZEN, protoze nejaky hypoteticky odstranovani hypotetickych bottlenecku je ptakovina, kdyz architektura je jaka je.HEAD píše:Hm 64 rops
to platí pro Nvidii, která má FP64 jednotky zvlášť. AMD počítá FP64 na FP32 jednotkách, takže rozdíl budou spíš jenom nějaké registry navíc a nejspíš nějaká větší instrukční cache. Proto je rozdíl tranzistorů mezi Vegou 10 a Vegou 20 tak malý, zbytek spolkly ECC, XGMI, a širší paměťový řadič.havli píše:Jen tak btw - vzdycky se tvrdilo, ze podpora rychleho FP64 stoji spoustu tranzistoru (a tim prenesene i plochy GPU). Jak je mozne, ze V10 vs V20 se lisi jen o 5% v poctu tranzistoru a to jeste neco z toho jiste pripada na dalsi zmeny ve V20? Pritom V10 umi FP64 v pomeru 1/16 a V20 1/2.
{kind=link}