


Moderátoři: flanker, Eddward, Baneshee






s tím se dá celkem souhlasit.The current architecture is not optimal for varied workloads, most especially not single-threaded or floating point calculations. AMD obviously spent most of its time optimizing this chip for server workloads because that's where the money is. Clearly, they didn't have the resources to work on a separate, desktop optimized version. Furthermore, the emphasis on multi-threaded integer performance while sharing the FPU bewteen two integer units demonstrates that AMD doesn't think the FPU in CPUs is long for this world, and I have to agree. When you see how fast a GPU runs single precision floating point calculations, you'd think twice about bothering to continue to waste CPU die space with ever-larger x87 FPU units, too. Basically, even a Radeon 5000-series or nVidia GTX400-series GPU will beat the crap out of an Intel i7 2600K or even a i7 980 when it comes to floating point calculations. The writing is on the wall, and AMD is moving in that direction. Any switch over in computing like this is going to be moderately painful (look at moving from 32 to 64 bit), but at least AMD is leading the way, as they often have been doing since the K7, while Intel sits back and watches, waiting to copy AMD once they look like they've gotten the formula right.




Když jsme o této variantě mluvili naposledy, ala využít k některým CPU instrukcím tranzistory z GPU, bylo to okamžitě smeteno ze stolu s tím, že mezi CPU a GPU je děsná díra a byly by to naprosto neakceptovatelný obrovský latence. A SP jak jsou teď nejsou x87, nedovedou dělat to samé, kor při stejné efektivitě. Kdyby ano, už v těch CPU dávno byly. A naopak, jedotky z CPU suxxujou v tom co dělá GPU, jak nám ukázalo Larabe. Prostě GPU jsou pořád neuniverzální specifický HW pro určité operace. Zuniverzálnění jejich čipů tak aby byly schopy provádět libovolný kód je možná, ale ztratil by jsi tak 75% grafického výkonu na tranzistor/odběr/plochu. Kdo si toho lízne jako první? Nevim, i Intel na to kapituloval.del42sa píše:ano, AMD nejspíš počítá s tím, že FPU ( ko-procesor ) do budoucna z CPU jako takového úplně zmizí a nahradí ho výpočetní jednotky podobné těm v grafických kartách. Čili x87 se přesune tam.
LLano je zatím spíše SoC než APU (dvě samostatné řešení na jednom křemíku) , Trinity možná bude umět tyhle dva světy trochu více spojit a zužitkovat (aby to nebylo jen CPU s integrovanou grafikou jako u Intelu), Kaveri APU by v tomto mohlo jít ještě dál....

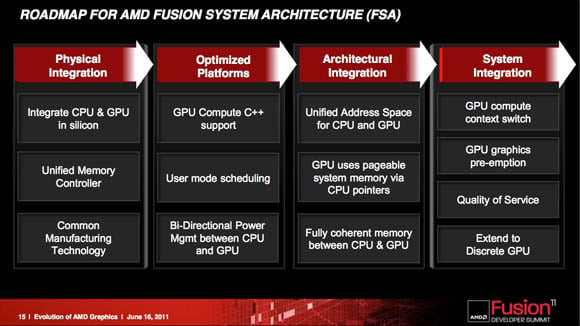
ale ja som neriešil výkon , to je logické, ale podporu softu ked nebude je fuk kde bude gk napchanáwebwalker píše:dexterav: No ono právě propojení cpu-gpu-ram je pro APU nebo gpgpu naprosto klíčovou záležitostí. Veškerá komunikace mezi cpu a gpu je zatím realizována prostřednictvím RAM. Pro vyšší programovací jazyky je třeba, aby cpu i gpu měla společný paměťový prostor (dnes virtuální RAM). Pokud tedy připojíš dGpu tak jako další mezičlánek se ti projeví PCIE. PCIE, ačkoliv není jednosměrná, s provozem od gpu směrem k cpu moc nepočítá, navíc PCIE je stavěna na bandwidth a nehledí moc na latence. Pokud jsem dobře pochopil plány AMD s APU, mají to rozvrženo takto:
1. generace - CPU a GPU na jednom die bez propojení PCIE (dnešní stav)
2. generace - CPU a GPU se společným paměťovým prostorem
3. generace - další začlenění gpu hlouběji do cpu (možná doplnění SP přímo k fpu)
přesně tak ! Slyšel jsi už o architektuře GCN ? Jsem si jist že ano. Zaměřím se teď jen ty podstatné části z představení GCN:webwalker píše:dexterav: No ono právě propojení cpu-gpu-ram je pro APU nebo gpgpu naprosto klíčovou záležitostí. Veškerá komunikace mezi cpu a gpu je zatím realizována prostřednictvím RAM. Pro vyšší programovací jazyky je třeba, aby cpu i gpu měla společný paměťový prostor (dnes virtuální RAM). Pokud tedy připojíš dGpu tak jako další mezičlánek se ti projeví PCIE. PCIE, ačkoliv není jednosměrná, s provozem od gpu směrem k cpu moc nepočítá, navíc PCIE je stavěna na bandwidth a nehledí moc na latence. Pokud jsem dobře pochopil plány AMD s APU, mají to rozvrženo takto:
1. generace - CPU a GPU na jednom die bez propojení PCIE (dnešní stav)
2. generace - CPU a GPU se společným paměťovým prostorem
3. generace - další začlenění gpu hlouběji do cpu (možná doplnění SP přímo k fpu)
The major change in the GCN’s shader array is that it includes what AMD calls the compute unit (CU), and what Demers calls the “cellular basis” of the design. A CU takes over the chores of the previous architecture’s VLIW-based SIMD (single-instruction-stream, multiple-data-stream) elements.
The CUs can work in virtual space, Demers says, and they’ll support the x86 64-bit virtual address space – more on that later. Observability of the CUs and the scalar processor, and support for the x86 virtual space – along with the fact that, Demers says, “you can load the PC from memory or from a register and do all kinds of math” – opens up such C++ features as virtual functions, recursions, and x86 dynamic linked libraries. “All of these become a native thing that this guy can support,” he says.
a new memory system is needed. In previous AMD GPU architectures, the memory system was a read-only cache; in the new architecture, it’s read-write. “It’s a generalized cache just like we have in CPUs,” he says.
The GCN also envisions conherency being handled between both CPU and GPU at the L2 level. “I’m talking probe traffic,” Demers says, “I’m talking all the usual stuff you’ve come to expect on coherency.” GPU CUs and CPU cores will find coherency at the L2 level. Discrete GPUs can join over PCIe
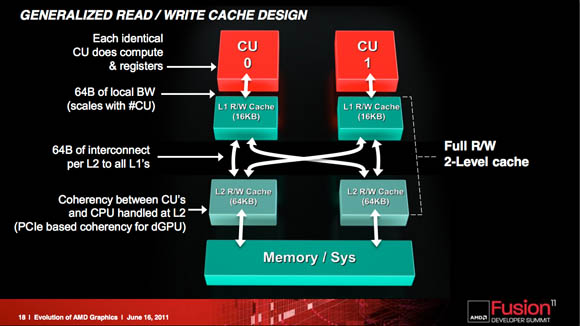
http://insidehpc.com/2011/07/07/deep-in ... ple-intel/x86 support, he says, means that “our GPUs have to have address-translation caches. Basically, they take virtual addresses and they translate that into physical addresses.” Address-translation caches already exist in AMD GPUs, but in the new architecture, they’ll be talking in x86 language.
http://developer.nvidia.com/openclOpenCL™ (Open Computing Language) is a low-level API for heterogeneous computing that runs on CUDA architecture GPUs. Using OpenCL, developers can write compute kernels using a C-like programming language to harness the massive parallel computing power of NVIDIA GPU’s to create compelling computing applications. As the OpenCL standard matures and is supported on processors from other vendors, NVIDIA will continue to provide the drivers, tools and training resources developers need to create GPU accelerated applications. April 2009: NVIDIA releases industry first OpenCL 1.0 GPU drivers for Windows and Linux, accompanied by the 100+ page NVIDIA OpenCL Programming Guide, an OpenCL JumpStart Guide showing developers how to port existing code from CUDA C to OpenCL, and OpenCL developer forums
{kind=link}