

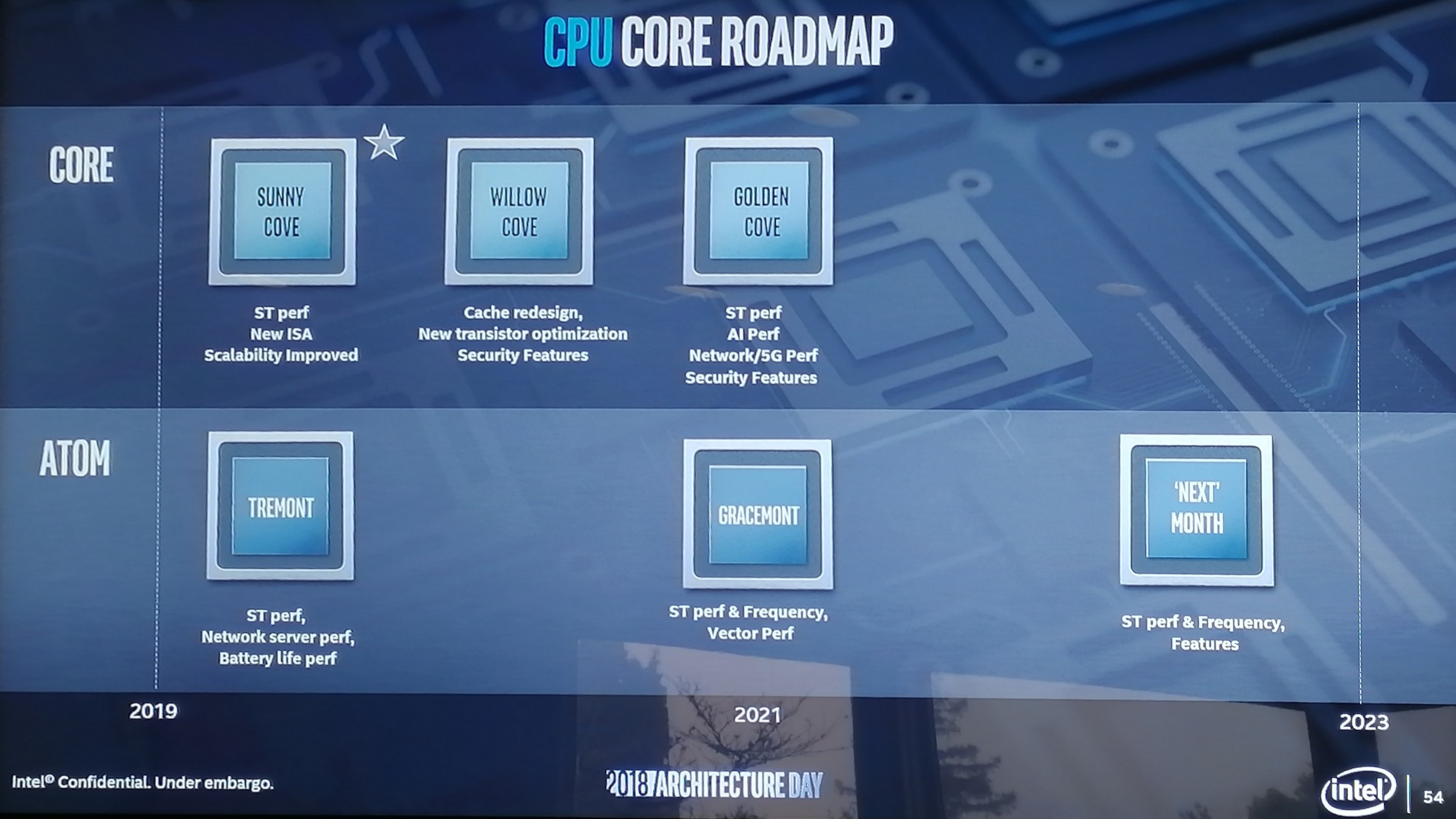
Jak jsem rikal, na Golden Cove jsem hodne zvedavej, ale hlavne z pohledu low latency a herniho vykonu, cisty compute vykon me v desktopu az tak nezajima. Intel rikal, ze GC muze tu sbernici (fabric) dynamicky "tunit" bud na vyssi propustnost, anebo pro lepsi latence. Stejne tak muze o kazdem bloku L3 rozhodovat, jestli bude inkluzivni, nebo ne. Pokud vim, tohle zatim zadna x86 desktop architektura nedelala, ne? Veci jako ringbus, mesh, nebo infinity fabric jsou "fixni", kde za vsech podminek operuji vzdycky v tom stejnem rezimu, naproti tomu ADL pouziva urcitou formu machine learningu, kde neustale analyzuje pouzite instrukce a dynamicky se rozhoduje, co presne udela, aby mel v danem workloadu co nejlepsi vykon, pripadne pomer vykon/watt.
Dost zajimave veci - snad o tom Intel brzy rekne neco vice. Zajimalo by me, kolik vykonu takovym inteligentnim chovanim dokazou nahnat.
Baneshee - promaz OT. Osobní narážky sem netahejte











{kind=link}