Stránka 1 z 31
AMD "Piledriver" Vishera refresh Zambezi -info,spekulace atd
Napsal: úte 25. říj 2011, 13:16
od flanker
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: stř 26. říj 2011, 11:37
od webwalker
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: stř 26. říj 2011, 15:13
od flanker
jj, 8170 by mohla být B3...ale zázrak nečekat (jen o něco OC a spotřeba)
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: stř 26. říj 2011, 20:21
od flanker

10% ?

...kdyby takt na takt, ale zas ta poznámka věští multithread...
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 16:45
od del42sa
Proč AMD zvolilo takovou architekturu u Bulldozeru ? Nejspíše kvůli heterogennímu computingu. AMD chce v budoucnu spojit výpočetní sílu shader procesorů u grafických karet se světem architektury x86 CPU.
The current architecture is not optimal for varied workloads, most especially not single-threaded or floating point calculations. AMD obviously spent most of its time optimizing this chip for server workloads because that's where the money is. Clearly, they didn't have the resources to work on a separate, desktop optimized version. Furthermore, the emphasis on multi-threaded integer performance while sharing the FPU bewteen two integer units demonstrates that AMD doesn't think the FPU in CPUs is long for this world, and I have to agree. When you see how fast a GPU runs single precision floating point calculations, you'd think twice about bothering to continue to waste CPU die space with ever-larger x87 FPU units, too. Basically, even a Radeon 5000-series or nVidia GTX400-series GPU will beat the crap out of an Intel i7 2600K or even a i7 980 when it comes to floating point calculations. The writing is on the wall, and AMD is moving in that direction. Any switch over in computing like this is going to be moderately painful (look at moving from 32 to 64 bit), but at least AMD is leading the way, as they often have been doing since the K7, while Intel sits back and watches, waiting to copy AMD once they look like they've gotten the formula right.
s tím se dá celkem souhlasit.
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 17:03
od flanker
to by bylo fajn, otázkou je kdy a nakolik to bude dotažené do konce...defakto o něco takového se přece snaží projekt Fusion.
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 17:13
od del42sa
ano, AMD nejspíš počítá s tím, že FPU ( ko-procesor ) do budoucna z CPU jako takového úplně zmizí a nahradí ho výpočetní jednotky podobné těm v grafických kartách. Čili x87 se přesune tam.
LLano je zatím spíše SoC než APU (dvě samostatné řešení na jednom křemíku) , Trinity možná bude umět tyhle dva světy trochu více spojit a zužitkovat (aby to nebylo jen CPU s integrovanou grafikou jako u Intelu), Kaveri APU by v tomto mohlo jít ještě dál....
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 17:28
od dexterav
Treba soft, ak nebude soft je to k nicomu a ten soft proste nieje. Uz sa to preberalo pri llane
A je jedno ci bude gk priamo v cpu alebo iba zapuzdrene vedla cpu. Amd neobjavilo nic nove
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 17:32
od DOC_ZENITH
del42sa píše:ano, AMD nejspíš počítá s tím, že FPU ( ko-procesor ) do budoucna z CPU jako takového úplně zmizí a nahradí ho výpočetní jednotky podobné těm v grafických kartách. Čili x87 se přesune tam.
LLano je zatím spíše SoC než APU (dvě samostatné řešení na jednom křemíku) , Trinity možná bude umět tyhle dva světy trochu více spojit a zužitkovat (aby to nebylo jen CPU s integrovanou grafikou jako u Intelu), Kaveri APU by v tomto mohlo jít ještě dál....
Když jsme o této variantě mluvili naposledy, ala využít k některým CPU instrukcím tranzistory z GPU, bylo to okamžitě smeteno ze stolu s tím, že mezi CPU a GPU je děsná díra a byly by to naprosto neakceptovatelný obrovský latence. A SP jak jsou teď nejsou x87, nedovedou dělat to samé, kor při stejné efektivitě. Kdyby ano, už v těch CPU dávno byly. A naopak, jedotky z CPU suxxujou v tom co dělá GPU, jak nám ukázalo Larabe. Prostě GPU jsou pořád neuniverzální specifický HW pro určité operace. Zuniverzálnění jejich čipů tak aby byly schopy provádět libovolný kód je možná, ale ztratil by jsi tak 75% grafického výkonu na tranzistor/odběr/plochu. Kdo si toho lízne jako první? Nevim, i Intel na to kapituloval.
Na druhou stranu Epic software předvídá do budoucna návrat k SW renderingu, že scéna už nebude renderována real-time přes GPU, jelikož rasterizace má svá omezení, ale že se vrátíme k cestě SW renderingu kterej budou provádět buďto hodně silná mnohojádrová CPU s vvysokym celkovym hrubym výkonem (ty tu ovšem zdaleka nemáme, musel by se současnej výkon zvednout alespoň 10x), nebo jiné specializované čipy s vysokou výpočetní silou. Přičemž dále komentovali launch Fermi jako první krok tímto směrem, ale jedním dechem bylo dodáno, že Fermi je pořád tak 4-5 generací mimo a na toto v praxi zdaleka nepoužitelná. Že je potřeba něco mnohem univerzálnějšího, komplexnějšího (co se týče instrukcí schopných vykonat) a rychlejšího.
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 17:35
od del42sa
Dexterav: a jak víš že na tom nepracují ? Llano bylo pro AMD spíše jen takové cvičení, zda je to vyrobitelné a jak se to bude chovat. Navíc Llano je fakt spíše SoC než APU, ale právě ty další APU by to mohly mít jinak (doufejme) a na tom jak to bude propojeno (GPU/CPU) sakra záleží a ne že je to jedno...
DOCENT si ještě jednou pořádně přečte moji zpávu napsanou v 17:13h a zkusí zapojit protentokrát mozek

Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 18:04
od dexterav
ako vravím nieje to vynález AMD, a dalšia vec to si myslíš že teraz všetky soft firmy začnú písať pre APU od AMD?
o týchto veciach sa nehovorí prvý deň
a ked už tak mali to robiť už pri vydaní llana a nič také sa nestalo, samozrejme je to super myšlienka ale už sa to rieši od doby 88GTX a nejaké extra pokroky tu niesú
a prečo by záležalo ako sú prepojené?
ved je to to isté ako teraz ATISTREAM alebo CUDA to že to niekto obalí do pekných a iných grafov na tom moc nezmení
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 21:26
od webwalker
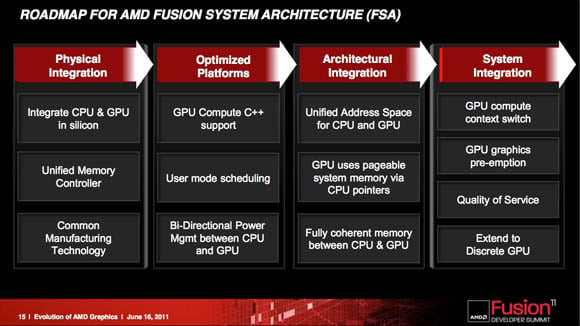
dexterav: No ono právě propojení cpu-gpu-ram je pro APU nebo gpgpu naprosto klíčovou záležitostí. Veškerá komunikace mezi cpu a gpu je zatím realizována prostřednictvím RAM. Pro vyšší programovací jazyky je třeba, aby cpu i gpu měla společný paměťový prostor (dnes virtuální RAM). Pokud tedy připojíš dGpu tak jako další mezičlánek se ti projeví PCIE. PCIE, ačkoliv není jednosměrná, s provozem od gpu směrem k cpu moc nepočítá, navíc PCIE je stavěna na bandwidth a nehledí moc na latence. Pokud jsem dobře pochopil plány AMD s APU, mají to rozvrženo takto:
1. generace - CPU a GPU na jednom die bez propojení PCIE (dnešní stav)
2. generace - CPU a GPU se společným paměťovým prostorem
3. generace - další začlenění gpu hlouběji do cpu (možná doplnění SP přímo k fpu)
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 21:33
od yuri.cs
Jenom doplnim, ze pokud je mi znamo, tak bod cislo 2 by teoreticky mel spadat do doby pusobeni iteraci architektury GCN.
...doba vyhradniho pouziti GPU jako koprocesoru pro paralelni vypocty je mnohem dal, nez BD a jeho vyvojove vetve.
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 21:38
od dexterav
webwalker píše:dexterav: No ono právě propojení cpu-gpu-ram je pro APU nebo gpgpu naprosto klíčovou záležitostí. Veškerá komunikace mezi cpu a gpu je zatím realizována prostřednictvím RAM. Pro vyšší programovací jazyky je třeba, aby cpu i gpu měla společný paměťový prostor (dnes virtuální RAM). Pokud tedy připojíš dGpu tak jako další mezičlánek se ti projeví PCIE. PCIE, ačkoliv není jednosměrná, s provozem od gpu směrem k cpu moc nepočítá, navíc PCIE je stavěna na bandwidth a nehledí moc na latence. Pokud jsem dobře pochopil plány AMD s APU, mají to rozvrženo takto:
1. generace - CPU a GPU na jednom die bez propojení PCIE (dnešní stav)
2. generace - CPU a GPU se společným paměťovým prostorem
3. generace - další začlenění gpu hlouběji do cpu (možná doplnění SP přímo k fpu)
ale ja som neriešil výkon , to je logické, ale podporu softu ked nebude je fuk kde bude gk napchaná
to je totiž presne to čo chýba masívna podpora softu
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 22:19
od del42sa
webwalker píše:dexterav: No ono právě propojení cpu-gpu-ram je pro APU nebo gpgpu naprosto klíčovou záležitostí. Veškerá komunikace mezi cpu a gpu je zatím realizována prostřednictvím RAM. Pro vyšší programovací jazyky je třeba, aby cpu i gpu měla společný paměťový prostor (dnes virtuální RAM). Pokud tedy připojíš dGpu tak jako další mezičlánek se ti projeví PCIE. PCIE, ačkoliv není jednosměrná, s provozem od gpu směrem k cpu moc nepočítá, navíc PCIE je stavěna na bandwidth a nehledí moc na latence. Pokud jsem dobře pochopil plány AMD s APU, mají to rozvrženo takto:
1. generace - CPU a GPU na jednom die bez propojení PCIE (dnešní stav)
2. generace - CPU a GPU se společným paměťovým prostorem
3. generace - další začlenění gpu hlouběji do cpu (možná doplnění SP přímo k fpu)
přesně tak ! Slyšel jsi už o architektuře GCN ? Jsem si jist že ano. Zaměřím se teď jen ty podstatné části z představení GCN:
The major change in the GCN’s shader array is that it includes what AMD calls the compute unit (CU), and what Demers calls the “cellular basis” of the design. A CU takes over the chores of the previous architecture’s VLIW-based SIMD (single-instruction-stream, multiple-data-stream) elements.
The CUs can work in virtual space, Demers says, and they’ll support the x86 64-bit virtual address space – more on that later. Observability of the CUs and the scalar processor, and support for the x86 virtual space – along with the fact that, Demers says, “you can load the PC from memory or from a register and do all kinds of math” – opens up such C++ features as virtual functions, recursions, and x86 dynamic linked libraries. “All of these become a native thing that this guy can support,” he says.
a new memory system is needed. In previous AMD GPU architectures, the memory system was a read-only cache; in the new architecture, it’s read-write. “It’s a generalized cache just like we have in CPUs,” he says.
The GCN also envisions conherency being handled between both CPU and GPU at the L2 level. “I’m talking probe traffic,” Demers says, “I’m talking all the usual stuff you’ve come to expect on coherency.” GPU CUs and CPU cores will find coherency at the L2 level. Discrete GPUs can join over PCIe
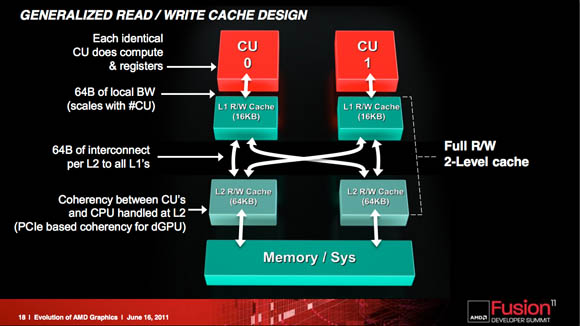
x86 support, he says, means that “our GPUs have to have address-translation caches. Basically, they take virtual addresses and they translate that into physical addresses.” Address-translation caches already exist in AMD GPUs, but in the new architecture, they’ll be talking in x86 language.
http://insidehpc.com/2011/07/07/deep-in ... ple-intel/
Takže ano, na způsobu propojení GPU a CPU záleží nejvíce ! Stejně tak na tom, jak dokážou tyto jednotky participovat na x86 jazyku a rozumět mu.
V Trinity tohle asi ještě neuvidíme, tam bude jako pomyslný "oslí můstek" mezi GPU a CPU sloužit pravděpodobně nějaký software na bázi Open CL (přímý konkurent CUDA)
Ale v další generaci APU kde bude použita GCN namísto WLIV4 už to pravděpodobně nebude vůbec potřeba, protože CPU a GPU budou schopné spolu komunikovat napřímo a GPU bude "rozumět" X86 a sdílet s ním paměťový prostor, což dnes nejde. V tomto světle by mohla dávat architektura Bulldozer větší smysl.
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 22:56
od DOC_ZENITH
AAgh... OpenCL neni žádná konkurence Cudy, je to jiné API, samaNV jej podporuje. Stav v OpenCL je takovej že nic nesjednotil ani nenormalizoval. Žádnej OpenCL kód neni. Doteď se vše musí psát přímo na architekturu toho či onoho GPU. Když to napíšu v OpenCL pro NV pojede to na ATI pomaleji než na CPU. Když to napíšu pro ATI, pojede to na NV pomaleji než na CPU. OpenCL nepřineslo nic univerzálního protože samotné GPU architektury jso unaprosto neuniverzální a naprosto nekompatibilní a neschopné zpracovávat ten samej kód.
Proto tady nemohu souhlasit se zapojením GPU do X87 operací. Naprosto na to neni dělané. Že ATI si dala do slajdů podporu C++? To Fermi umí už teď a bylo jí to k něčemu?..... a víme jak ty jejich slajdy dopadaj. Od roku 2006 na CPU scéně samej doslova trhač asfaltu. Možná za další 2+ generace GPU a CPU budou schopny chytit a efektivně dělat jeden kód, ale do té doby budu šedivej (s přihlédnutím k tomu jak pomalu se dnes architektury mění) a vše se může změnit. Tím nemá cenu se vůbec zatěžovat. Využívání paměti a L2 s GPU.... to nám jejich výpočetní jednotky a schopnosti niak nesjednotí.
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 23:20
od del42sa
DOCENTE, CUDA je uzavřený standart Nvidie, Open CL je otevřené API, které může fungovat téměř na všem. Právě proto nVidia přeportovala CUDA API na OpenCL pro ty, kteří z nějakého důvodů nechtějí CUDA používat kvůli jeho uzavřenosti. To že to Nvida udělala jedině dokazuje to , že sama nepovažuje Open CL za zbytečný. Opět děláš stejnou chybu a generalizuješ svoje subjektivní názory


Zbytek raději nebudu komentovat, protože tvé nahlížení na některé skutečnosti je silně neobjektivní...
OpenCL™ (Open Computing Language) is a low-level API for heterogeneous computing that runs on CUDA architecture GPUs. Using OpenCL, developers can write compute kernels using a C-like programming language to harness the massive parallel computing power of NVIDIA GPU’s to create compelling computing applications. As the OpenCL standard matures and is supported on processors from other vendors, NVIDIA will continue to provide the drivers, tools and training resources developers need to create GPU accelerated applications. April 2009: NVIDIA releases industry first OpenCL 1.0 GPU drivers for Windows and Linux, accompanied by the 100+ page NVIDIA OpenCL Programming Guide, an OpenCL JumpStart Guide showing developers how to port existing code from CUDA C to OpenCL, and OpenCL developer forums
http://developer.nvidia.com/opencl
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 23:24
od webwalker
Yuri: díky
del42sa: úplný doktorát
 dexterav
dexterav: V tom máš pravdu. Vývoj ekosystému pro APU AMD poněkud zaspalo. Ono ale také hodně záleží na vývojových nástrojích, jinak se na to programátoři vykašlou, nebo budou podporováni jen určitou firmou, která si na tom bude přihřívat vlastní polévku. Ale řekl bych, že už by se mohlo blýskat na lepší časy.
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 23:25
od DOC_ZENITH
Ano já řikám že OpenCL je jen API, dále se furt musí optimalizovat pro konkrétní čipy, což prostě je pravda. Nejde aplikaci napsat "prostě na openCL" aby fungovala na všech čipech co uměl OpenCL. Ona se spustí, ale bude tak slow že to nemá smysl, a ve finále se stejně musí psát přímo na čip, pokud chceš využít síly GPU. Ano je to něco jako psát programy v C++, je to jazyk, ale jestli to napíšeš pro 8 threadů s použitím nejnovějších SSE instrukcí a nebo 1 thread přes x86 a x87 je už na tobě, to už je ta optimalizace. Problém je že u CPU stačí najít společné rysy, společně podporované instrukce a jedeš a SW pojede solidně na všem. Kdežto u GPU ne, GPU ATI a NV nemaj společného skoro nic, jsou to naprosto rozdílné architektury které nedovedou šežrat kód psanej pro tu druhou a nedovedou podávat jakkoliv solidní výkon pokud kód neni ušitej přímo jim na míru. A Řekni že tohle neni pravda.
Re: AMD "Piledriver" refresh Zambezi - info,spekulace atd
Napsal: čtv 27. říj 2011, 23:31
od webwalker
DOC_ZENITH: S tím OpenCL pro AMD nebo nVidii je to asi takhle. Aplikace napsaná pod OpenCL (pokud je napsaná správně) bude samozřejmě chodit jak na gpu nVidie tak na gpu AMD.
Problém je v tom, že AMD využívá VLIW a nVidia skaláry, takže pokud je OpenCL aplikace psaná s přihlédnutím na VLIW, pak samotná aplikace běží rychleji na gpu AMD. No a samozřejmě také naopak.


